(译)在 Go 解析器中因误用引发的意料之外的安全问题
Unexpected security footguns in Go's parsers
(译)Unexpected security footguns in Go’s parsers - 在 Go 解析器中因误用引发的意料之外的安全问题
目录
本文翻译自 Vasco Franco 的 Unexpected security footguns in Go’s parser, 原文链接:https://blog.trailofbits.com/2025/06/17/unexpected-security-footguns-in-gos-parsers/
在Go应用程序中,解析不可信数据会敞开一个相当危险的攻击面,这在现实环境中经常被利用。在我们的安全评估中,我们反复利用Go的JSON、XML和YAML解析器中的意外行为来绕过身份验证、规避授权控制,并从生产系统中窃取敏感数据。
这些不仅仅是停留在纸面上的问题——它们已经导致了记录在CVE数据库中的漏洞,如 CVE-2020-16250(由Google的Project Zero发现的Hashicorp Vault身份验证绕过)以及我们在客户与客户交流的过程中发现的大量高危问题。
本文通过三个攻击场景来阐述这些工程师预期之外的解析器行为,每个安全工程师和Go开发者都应该了解:
- (反)序列化意料之外的数据:Go解析器如何暴露开发者本打算保持私密的数据
- 解析器差异:当多个服务解析相同输入时,解析器之间的差异如何使攻击者能够绕过安全控制
- 数据格式混淆:解析器如何处理跨格式的有效载荷,产生令人惊讶且可利用的结果
我们将通过真实案例演示每个攻击场景,并以更安全地配置这些解析器的具体建议作为结束,包括缓解Go标准库中安全漏洞的策略。
以下是我们将要进行审查的可能会出现预期之外行为的列表,表中带有表示其安全状态的指示器:
🟢 绿色:默认安全 🟠 橙色:默认不安全但可配置 🔴 红色:默认不安全且无安全配置选项
| JSON | JSON v2 | XML | YAML | |
|---|---|---|---|---|
| json:"-,…" | YES (bad design) | YES (bad design) | YES (bad design) | YES (bad design) |
| json:“omitempty” | YES (expected) | YES (expected) | YES (expected) | YES (expected) |
| Duplicate keys | YES (last) | NO | YES (last) | NO |
| Case insensitivity | YES | NO | NO | NO |
| Unknown keys | YES (mitigable) | YES (mitigable) | YES | YES (mitigable) |
| Garbage leading data | NO | NO | YES | NO |
| Garbage trailing data | YES (with Decoder) | NO | YES | NO |
在Go中进行解析
让我们看看在Go如何解析JSON、XML和YAML结构化文档。Go的标准库向开发者提供了JSON和XML解析器,但没有提供YAML解析器,有几种第三方的替代方案。在我们的分析中,我们将重点关注:
- encoding/json版本go1.24.1
- encoding/xml版本go1.24.1
- yaml.v3版本3.0.1(最流行的第三方Go YAML库)
我们将使用JSON格式作为后续示例,但所有三种解析器都有与我们看到的API等效的API。
这些解析器提供两个核心功能:
Marshal(序列化):将Go结构体转换为各自结构的字符串Unmarshal(反序列化):将结构字符串转换回Go结构体
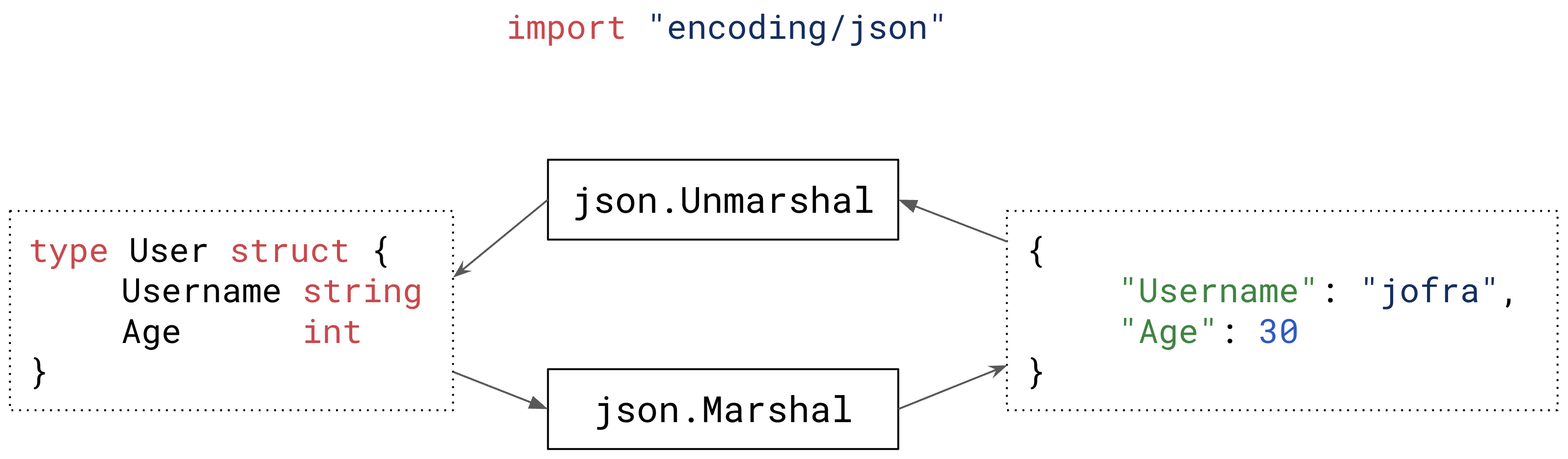
Go使用结构体字段标签来帮助开发者自定义解析器如何处理各个字段。这些标签包括:
- 用于决定序列化/反序列化的键名
- 修改行为的可选逗号分隔指令(例如,
omitempty标签选项告诉JSON序列化器如果字段为空则不包含在JSON输出字符串中)
|
|
要将JSON字符串反序列化为上面显示的User结构,我们必须对Username字段使用username_json_key键,对Password字段使用password键,对IsAdmin字段使用is_admin键。
|
|
这些解析器还提供了基于流的替代方案,这些方案在io.Reader接口上操作,而不是字节切片。这个API非常适合解析流数据,如HTTP请求体,使其成为HTTP请求处理的首选。

攻击场景1:(反)序列化意料之外数据
在某一些应用场景下,开发者需要决定哪一些字段需要进行序列化而哪一些不需要。
让我们考虑一个简单的例子,其中后端服务器有一个用于创建用户的HTTP处理程序,另一个用于在身份验证后检索该用户。
当创建用户时,您可能不希望用户能够设置IsAdmin字段(即从不受信任的用户输入中反序列化该字段)。
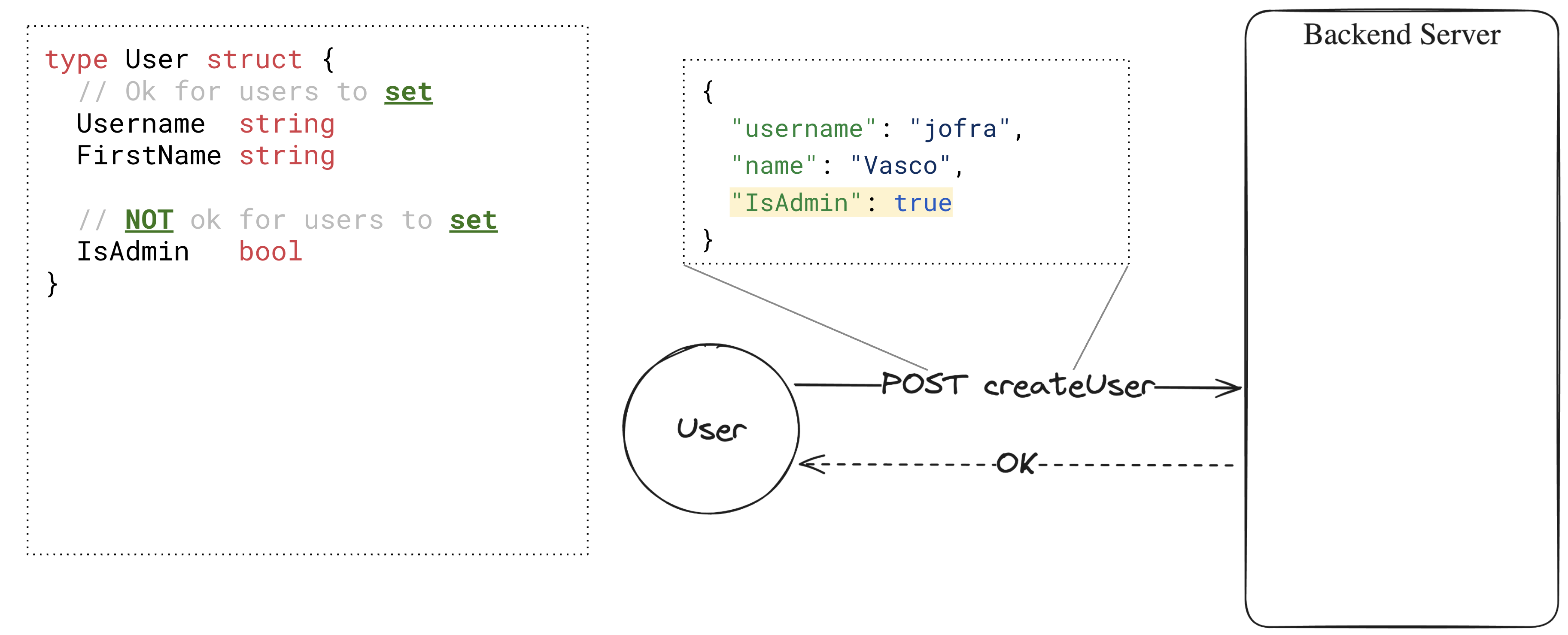
同样,当获取用户时,您可能不希望返回用户的Password或其他秘密值。
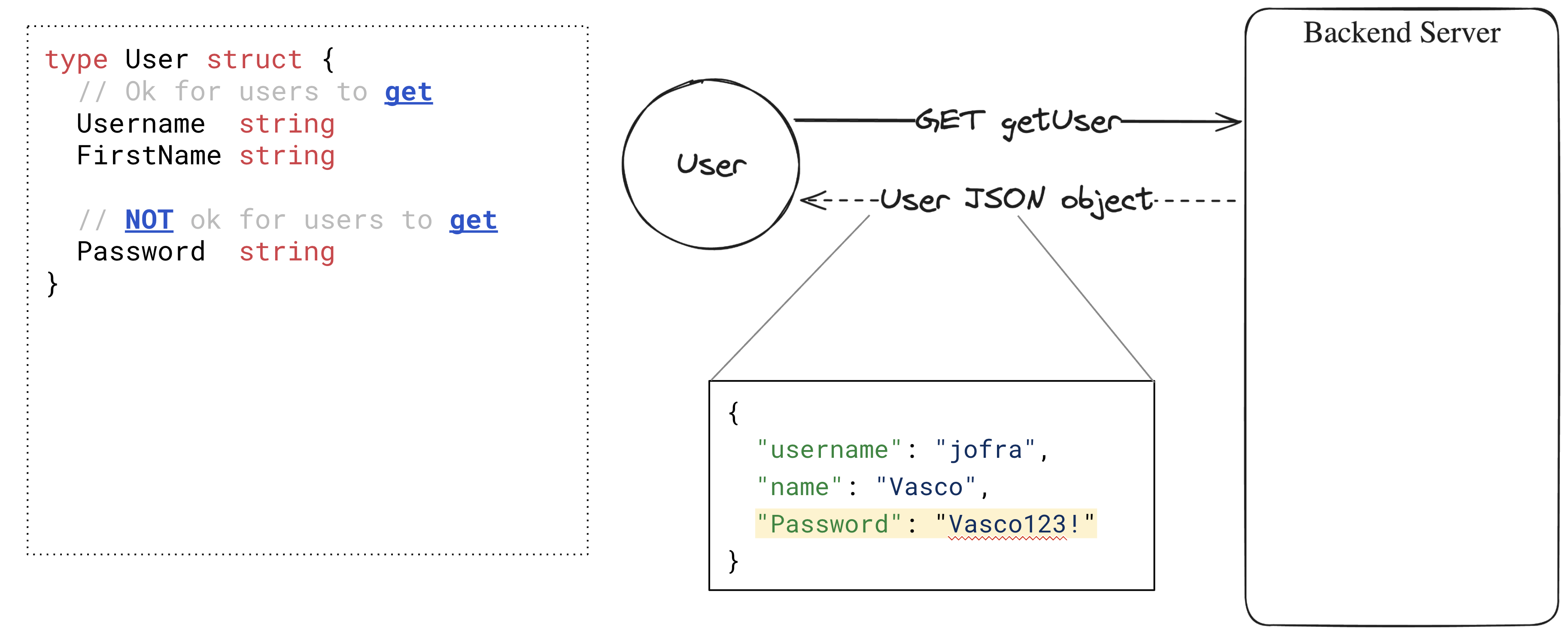
我们应该如何指示解析器不要序列化或反序列化哪些字段?
没有标签的字段
首先看看如果不设置JSON标签会发生什么。
|
|
在这种情况下,您可以使用其名称反序列化Username字段,如下所示。
|
|
这是有文档记录的,大多数Go开发者都知道。让我们看另一个例子:
|
|
上面的IsAdmin字段是否会被反序列化?一个不太资深或大意的开发者可能会认为不会,而实际上,这个字段是会被进行反序列化的,从而引入安全漏洞。
如果您希望扫描代码库中部分字段带有JSON/XML/YAML标签而其他字段没有的模式,可以使用以下Semgrep规则。该规则未发布在我们的Semgrep官方规则集中,因为根据代码库的不同,它可能会产生较多误报。
|
|
错误地使用 - 标签
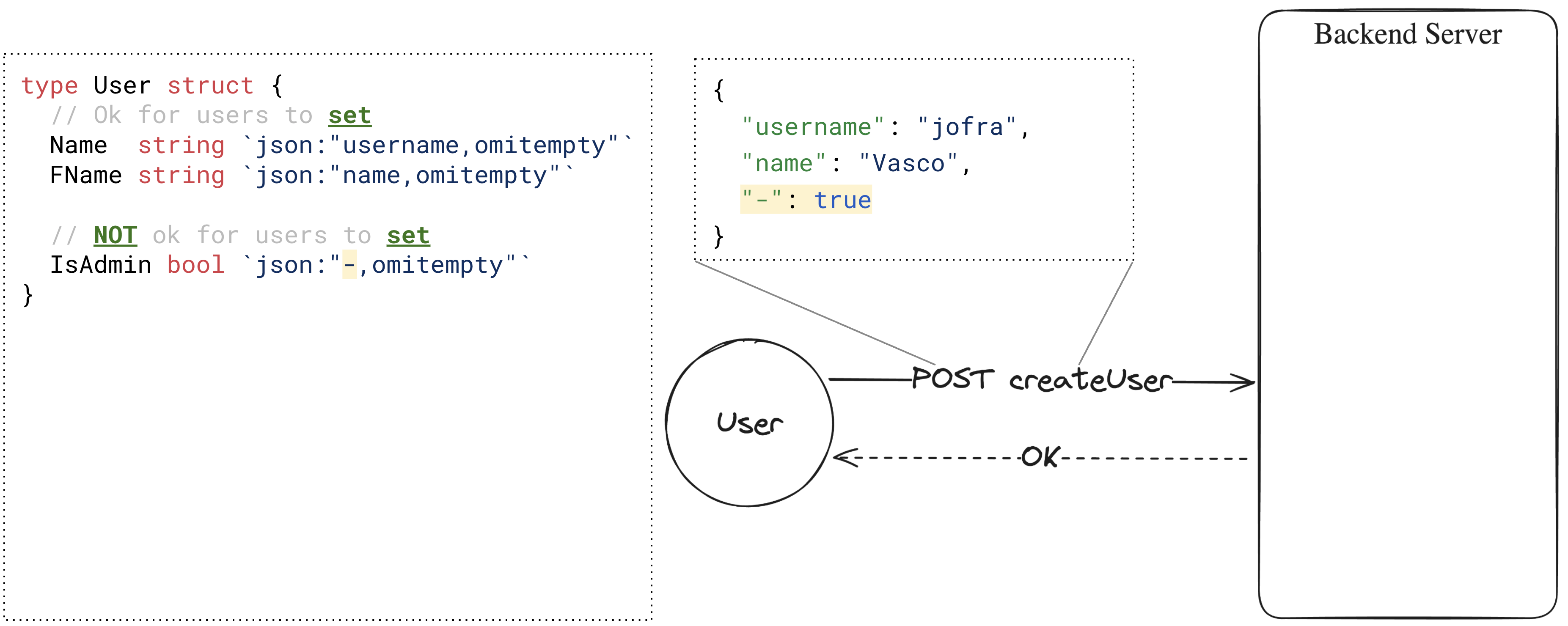
要告诉解析器不要(反)序列化特定字段,我们必须添加特殊的 - JSON标签!
|
|
让我们试试!
|
|
哦,糟糕,我们仍然能够设置IsAdmin字段。我们错误地复制粘贴了,omitempty的部分,这导致解析器在提供的JSON输入中查找-键。我在 GitHub 上按 star 数排名前 1,000 的 Go 仓库中搜索了这种模式,发现并报告了以下两个案例(均已修复):
- Flipt 在 OIDC 配置中暴露了ClientID字段,错误地使用了-作为字段名(修复 PR #3658)
- langchaingo 暴露了MaxTokens字段,错误地使用了-作为字段名(修复 PR #1163)
尽管这种行为容易出错且几乎没什么实际用途(允许将字段命名为-),但它确实在 Go 的**encoding/json**官方文档 中有明确说明:
As a special case, if the field tag is “-”, the field is always omitted. Note that a field with name “-” can still be generated using the tag “-,”.
XML 和 YAML 解析器的工作方式类似,但有一个关键区别:XML 解析器将<-> 标签视为无效。为了解决这个问题,我们必须在 - 符号前加上 XML 命名空间,例如 <A:-> 。

这次咱们就做得妥妥当当的,正确标注JSON结构的字段标签
|
|
终于!现在,IsAdmin 字段不可能被反序列化了。
但我听到您在问:这些错误配置是如何导致安全漏洞的?最常见的途径就像我们上面的例子那样,将 -,... 作为诸如 IsAdmin 这样的字段的 JSON 标签——这是一个用户不应控制的字段。这种错误很难通过单元测试检测出来,因为除非您有一个明确的测试,能够对包含 - 这个键的输入进行反序列化,并检测是否有任何字段被写入,否则您无法发现它。您需要您的集成开发环境(IDE)或外部工具来检测它。
我们创建了一条公共的 Semgrep 规则,以帮助你在代码库中查找类似的问题。可以使用以下命令尝试:semgrep -c r/trailofbits.go.unmarshal-tag-is-dash。
错误地使用omitempty
我们还发现了一个非常简单的错误配置,开发人员错误地将字段名设置为omitempty。
|
|
如果将 JSON 标签设置为omitempty,解析器会将omitempty用作字段的名称(如预期)。当然,有些开发人员试图使用它来为字段设置omitempty选项,同时保留默认名称。我在 GitHub 上搜索了按星数排名前 1000 的 Go 仓库,发现了以下结果:
- Gitea 将TranslatableMessage结构体的Args字段暴露为omitempty键(已在 #33663 中修复)
- Kustomize 将plugin结构体的Replacements字段暴露为omitempty键(已在 #5877 中修复)
- Btcd 将TestMempoolAcceptCmd结构体的MaxFeeRate字段暴露为omitempty键
- Evcc 将Measurements结构体的Message字段暴露为omitempty键
在这些情况下,开发人员通常希望将标签设置为json:",omitempty",这将保留默认名称,并添加omitempty标签选项。
与前面的例子不同,这个例子不太可能产生安全影响,并且应该可以通过测试轻松检测到,因为任何尝试序列化或反序列化带有预期字段名的外部输入都会失败。然而,正如我们所见,它仍然出现在流行的开源仓库中。我们创建了一条公共的 Semgrep 规则,帮助你在代码库中查找类似的问题。可以使用以下命令尝试:semgrep -c r/trailofbits.go.unmarshal-tag-is-omitempty!
攻击场景 2:解析器差异
如果你使用不同的 JSON 解析器解析相同的输入,而它们对结果的看法不一致,会发生什么?更具体地说,Go 解析器中的哪些行为允许攻击者“可靠地”触发这些差异?
例如,让我们使用以下使用微服务架构的应用程序:
- 一个代理服务,接收所有用户请求。
- 一个授权服务,由代理服务调用以确定用户是否有足够的权限完成其请求。
- 多个业务逻辑服务,由代理服务调用以执行业务逻辑。
在第一个流程中,一个普通非管理员用户尝试执行一个UserAction,这是一个他们被允许执行的操作。
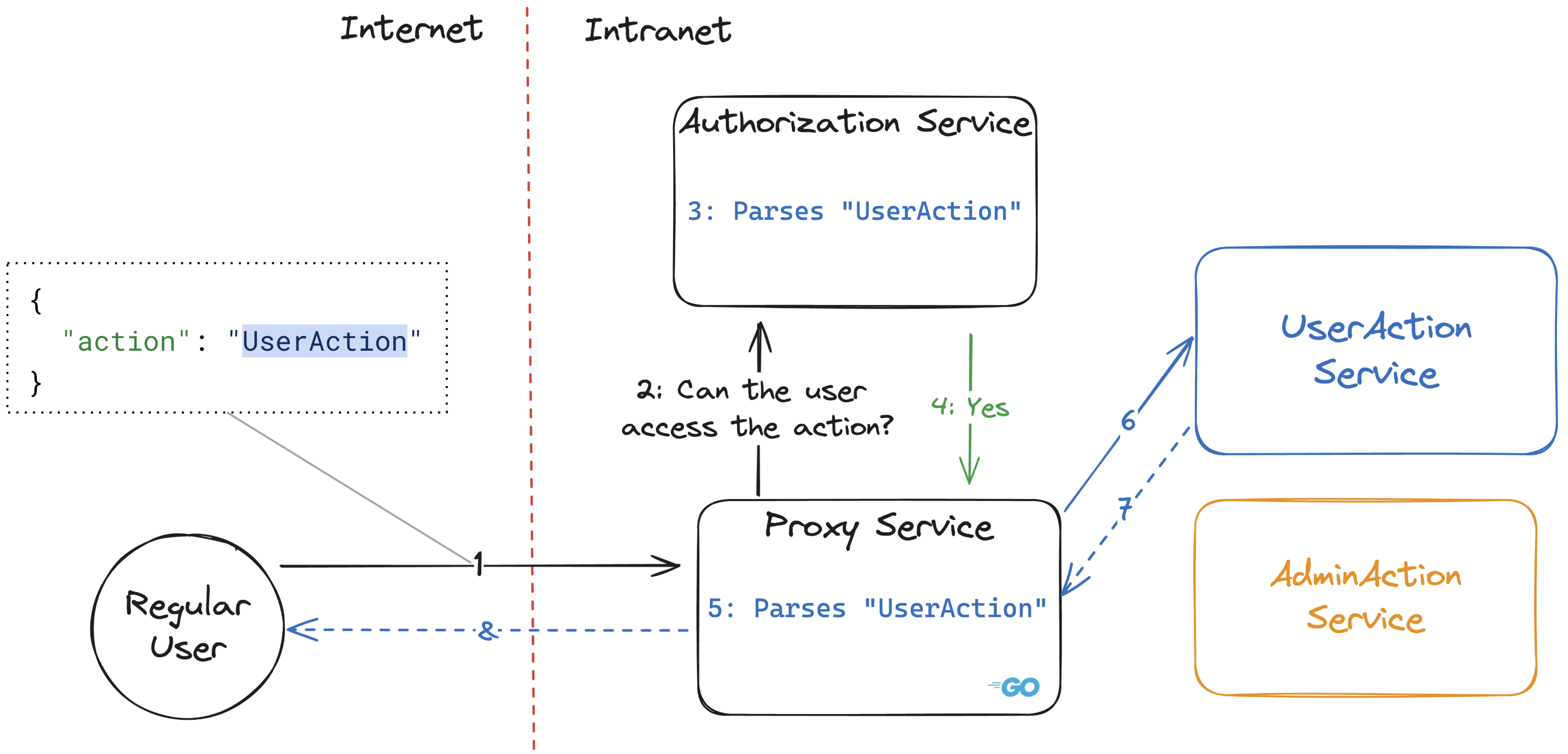
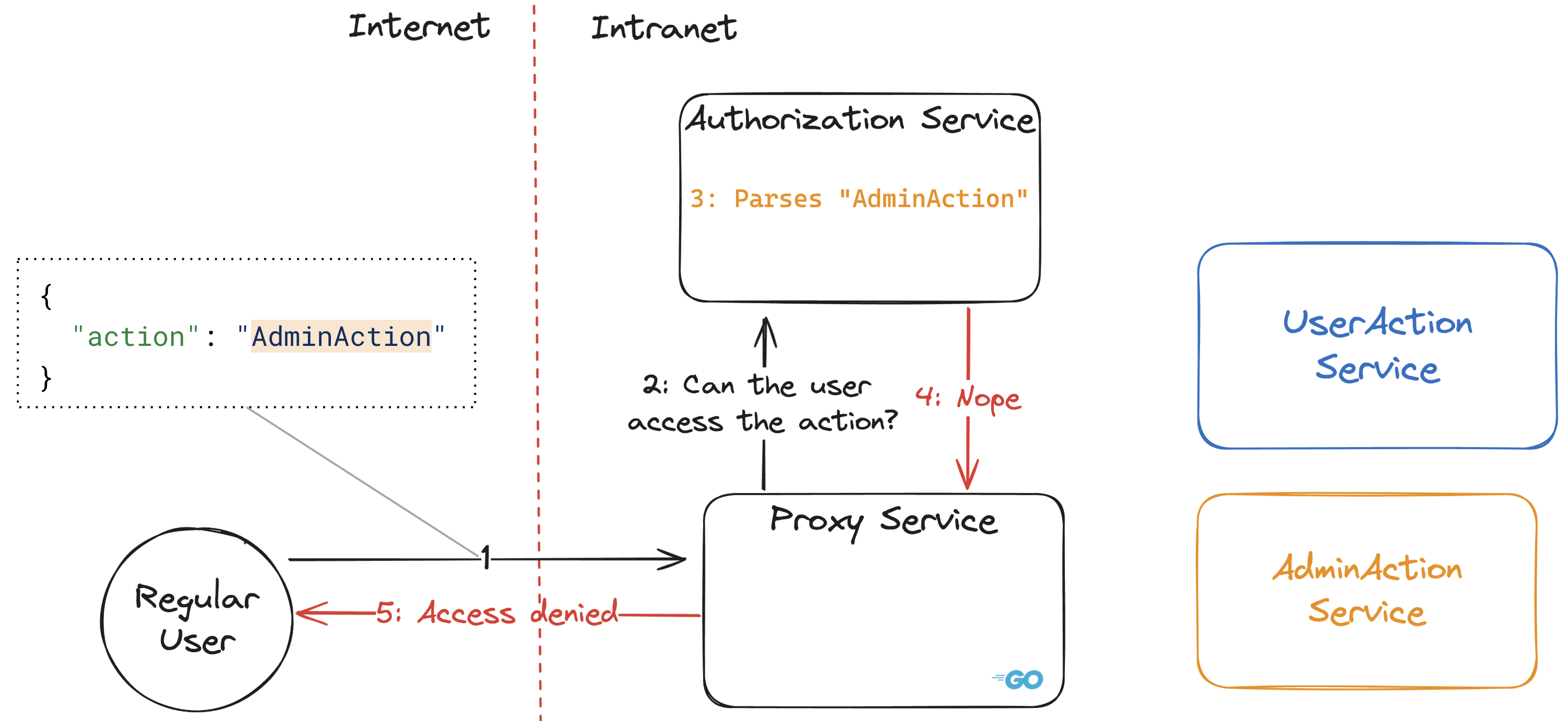
在第二个流程中,同一个普通用户尝试执行一个AdminAction,这是一个他们被禁止执行的操作。
最后,以下流程展示的是服务对用户尝试执行的操作意见不一致。
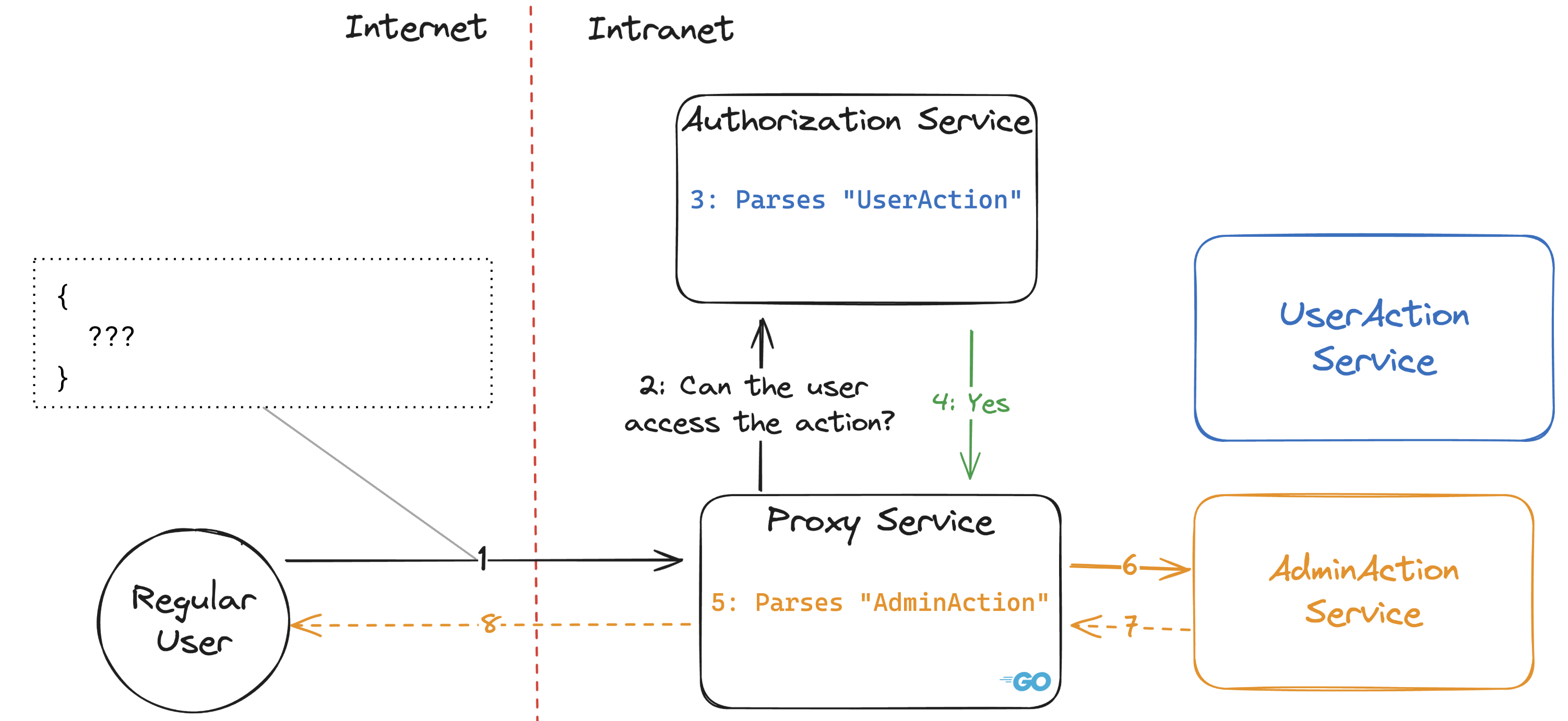
我们多次在审计中遇到这种常见架构,并且由于我们将在下文中描述的问题,我们发现了身份验证绕过的问题。还有其他例子,但大多数遵循相同的模式:执行安全检查的组件和执行操作的组件对输入数据的看法不同。以下是各种场景中的一些例子:
- CVE-2017-12635:Apache CouchDB 中由于 JSON 解析器差异导致的授权绕过(非常类似于我们上面的例子)
- MacOS 沙箱逃逸,由 XML 解析器差异导致(2020 年)
- Zoom 0 点击 RCE,由 XMPP 中的 XML 解析器差异导致(2022 年)
- GitLab SAML 身份验证绕过,由 XML 解析器差异导致(2025 年)
重复字段
我们首先探讨的第一个差异攻击向量是重复键(Key)。当你的 JSON 输入中同一个键出现两次时会发生什么?这取决于解析器的默认设计行为!
在 Go 中,JSON 解析器将始终取最后一个。没有办法阻止这种行为。
|
|
这是大多数解析器的默认行为。然而,正如 Bishop Fox 的 JSON 互操作性漏洞博客文章中所展示的那样,测试的 49 个解析器中有 7 个取第一个键:
- Go:jsonparser 和 gojay
- C++:rapidjson
- Java:json-iterator
- Elixir:Jason 和 Poison
- Erlang:jsone
这些都不是它们对应语言中最常用的 JSON 解析器,尽管有些是常见的替代品。
因此,如果我们的代理服务使用 Go JSON 解析器,而授权服务使用上述这些解析器之一,我们就会得到在这种架构下产生的各微服务对用户输入的释意不一致,如下图所示。
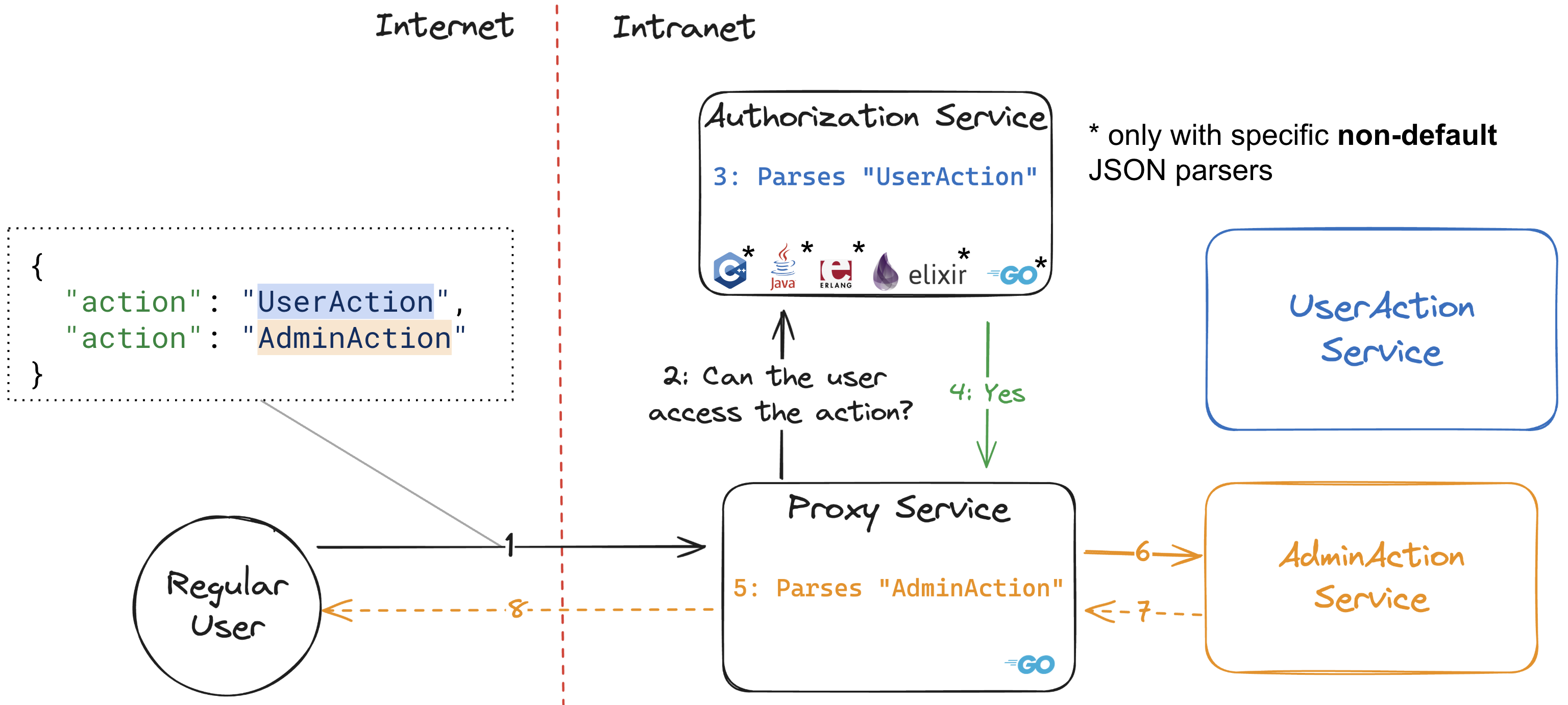
XML 解析器的行为与JSON解析器相同,而 YAML 解析器会在重复字段上返回错误——我们认为所有这些解析器都应该实现的安全默认行为。

尽管并不理想,但至少这种行为与最常用的 JSON 和 XML 解析器一致。现在让我们来看一个更糟糕的行为,这几乎总是会在 Go 的默认解析器和任何其他解析器之间产生差异。
不区分大小写的键匹配
Go 的 JSON 解析器以不区分大小写的方式解析字段名。无论你写的是action、ACTION还是aCtIoN,解析器都将它们视为相同的字段!
|
|
这是有文档说明的,但非常不符合直觉,没有办法禁用它,而且几乎没有其他解析器具有这种行为。
更糟糕的是,正如我们上面看到的,你可以有重复的字段,而最后一个仍然被选择,即使大小写不匹配。
|
|
这与文档相悖,文档中说:
“To unmarshal JSON into a struct, Unmarshal matches incoming object keys to the keys used by Marshal (either the struct field name or its tag),preferring an exact match but also accepting a case-insensitive match.”
你甚至可以使用 Unicode 字符!在下面的例子中,我们使用ſ(名为拉丁小写字母长 s 的 Unicode 字符)作为s,使用K(开尔文符号的 Unicode 字符)作为k。从我们对执行比较的 JSON 库代码的测试来看,只有这两个 Unicode 字符与 ASCII 字符匹配。
|
|
将其应用于我们正在进行的攻击场景中,下图是该攻击场景看起来的样子:
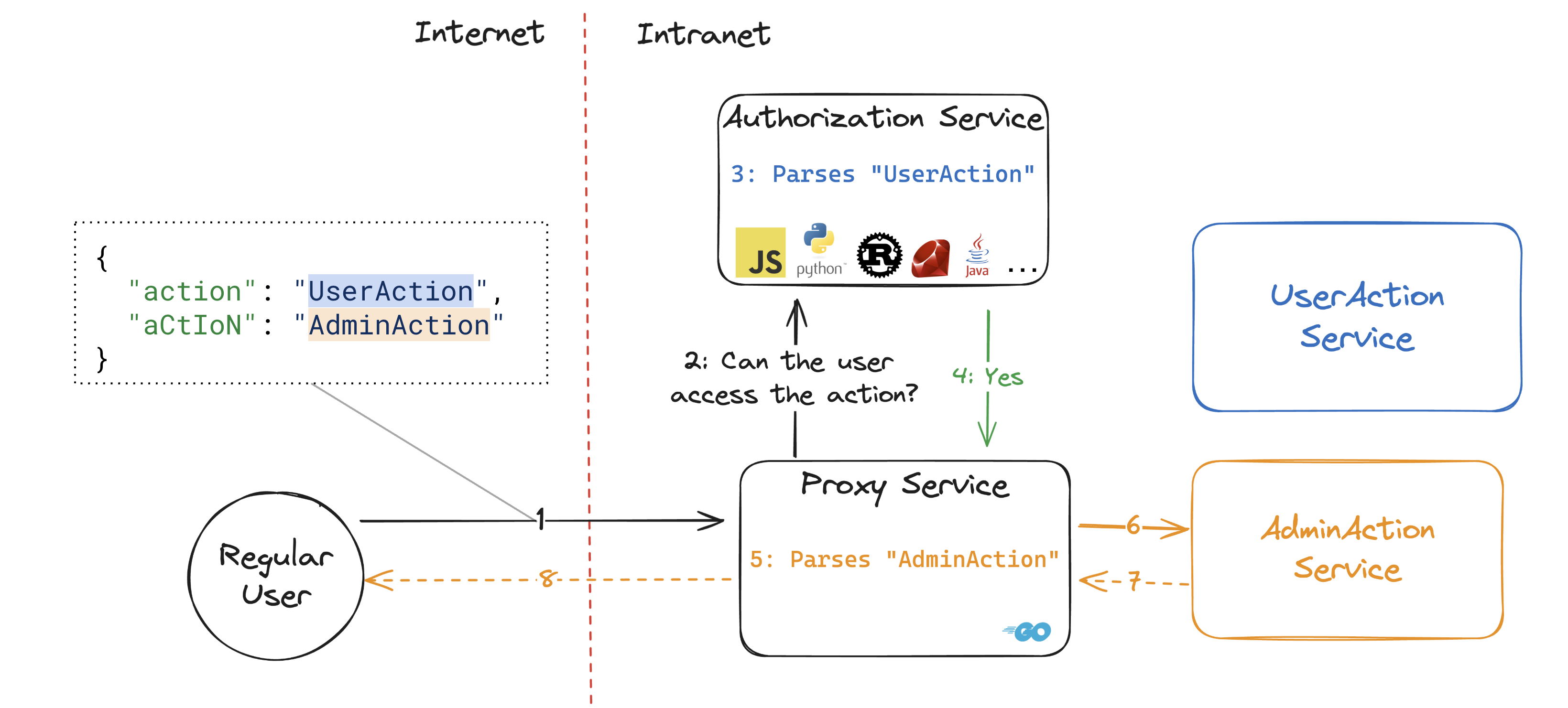
在我们看来,这是 Go JSON 解析器中最关键的陷阱,因为它与我们测试的 JavaScript、Python、Rust、Ruby、Java 等所有其他语言的默认解析器不同。这已经导致了许多高影响的安全漏洞,包括我们在审计中发现的漏洞。
令人感到遗憾的是,没有办法禁用这种行为,尽管自 2016 年以来,人们一直在抱怨这种行为导致的安全漏洞。
这仅影响 JSON 解析器。XML 和 YAML 解析器使用精确匹配。

如果你对许多解析器之间的 JSON 解析差异感兴趣,我们推荐以下两篇博客文章:
- Parsing JSON is a Minefieldby Nicolas Seriot
- JSON Interoperability Vulnerabilitiesby Bishop Fox
攻击场景 3:数据格式混淆
在最后一个攻击场景中,让我们看看如果用 XML 解析器解析 JSON 文件,或者用错误的解析器解析其他格式会发生什么。
例如,让我们使用 CVE-2020-16250,这是 Hashicorp Vault 的 AWS IAM 身份验证方法中的一个绕过漏洞。这个漏洞是由谷歌 Project Zero 团队发现的,如果你感兴趣,可以在他们的 “Enter the Vault: Authentication Issues in HashiCorp Vault” 博客文章中找到详细分析。我们不会在这篇文章中详细介绍所有细节,但总结来说,正常的 Hashicorp Vault AWS IAM 身份验证流程如下:
- 一个 AWS 资源(例如,AWS Lambda 函数)预签名了一个 GetCallerIdentity 请求。
- AWS 资源将其发送到 Vault 服务器。
- Vault 服务器构建该请求并将其发送到 AWS 安全令牌服务(STS)。
- AWS STS 验证签名。
- 验证成功后,AWS STS 以 XML 文档的形式返回与角色关联的身份。
- Vault 服务器解析 XML,提取身份,如果该 AWS 角色应该有权访问请求的机密,则返回机密。
- AWS 资源现在可以使用机密,例如,用于对数据库进行身份验证。
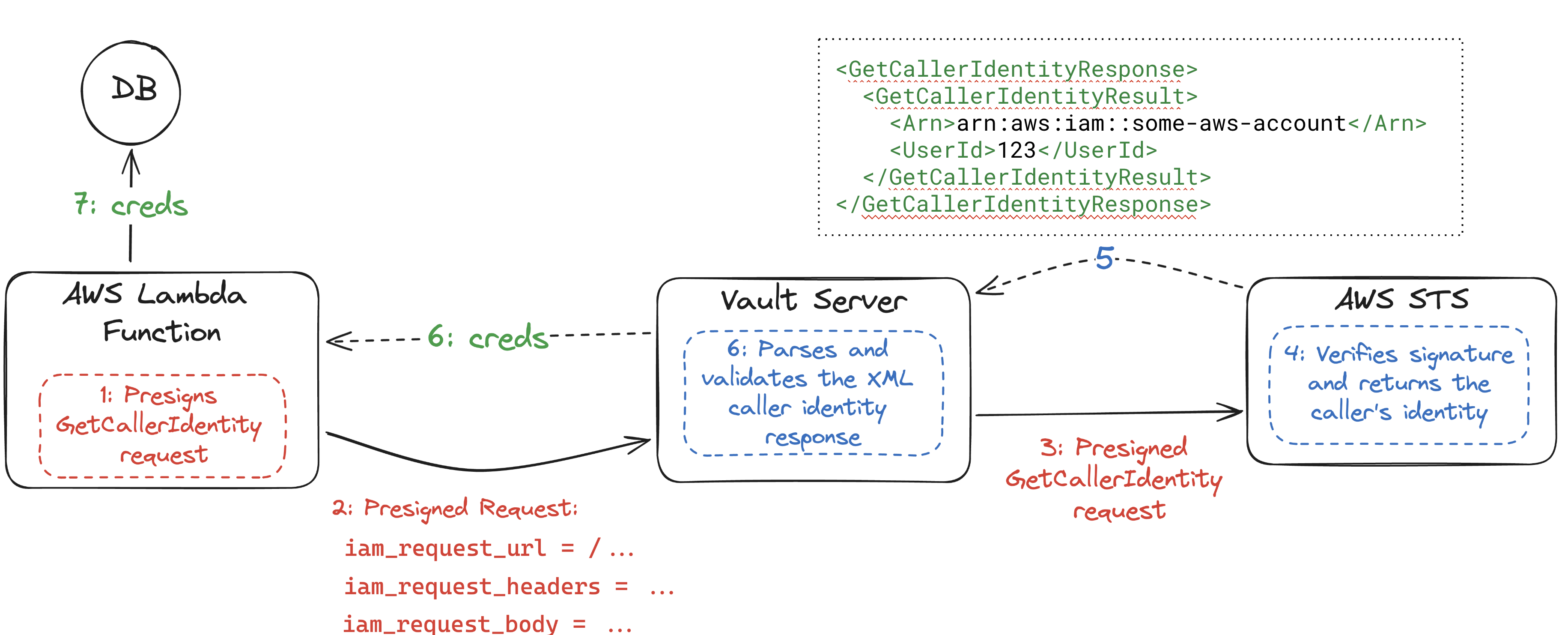
谷歌 Project Zero 团队发现,攻击者可以在第 2 步中控制大多数内容,包括控制 Vault 在第 3 步中构建的请求的所有头信息。特别是,通过将Accept头设置为application/json,AWS STS 现在将在第 5 步中返回一个 JSON 文档,而不是预期的 XML 文档。因此,Vault 服务器会用 Go 的 XML 解析器解析一个 JSON 文档。由于 XML 解析器非常宽松,它会在大量其他“垃圾”数据之间解析任何看起来像 XML 的内容,这在与对 JSON 响应的部分控制相结合时,足以实现完整的身份验证绕过。
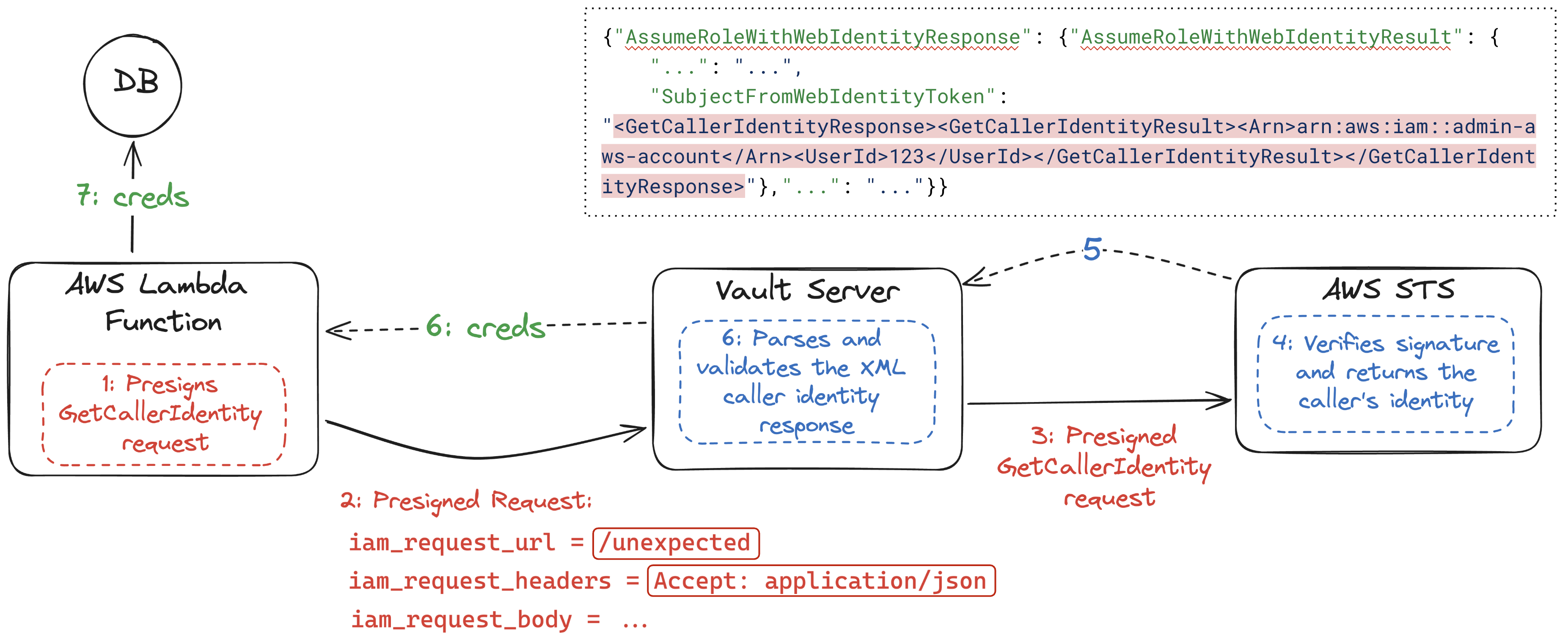
让我们来看三种不同的行为,这些行为使得用错误的 Go 解析器解析文件成为可能,并构建一个可以被 Go 的 JSON、XML 和 YAML 解析器解析并为每种解析器返回不同结果的多语言文件。
Unknown keys
默认情况下,JSON、XML 和 YAML 解析器不会阻止未知字段——传入数据中与目标结构体字段不匹配的属性。

前置垃圾数据
在三种解析器中,只有 XML 解析器接受前置垃圾数据。

后置垃圾数据
同样,只有 XML 解析器接受任意的后置垃圾数据。
唯一的例外是使用解析器的 Decoder API 与流式数据一起使用时,此时 JSON 解析器会接受后置垃圾数据。这是一个尚未计划修复的已知问题。

构建多语言文件
我们如何结合我们迄今为止看到的所有行为来构建一个多语言文件,使其:
- 可以被 Go 的 JSON、XML 和 YAML 解析器解析
- 为每种解析器返回不同的结果
一个非常有用的信息是 JSON 是 YAML 的一个子集:
每个 JSON 文件也是一个有效的 YAML 文件
考虑到这一点,我们可以构建以下多语言文件:

JSON 解析器可以解析多语言文件,因为输入是有效的 JSON,它忽略未知键,并允许重复键。它取Action_2的值,因为它的字段匹配不区分大小写,并且它取最后一个匹配的值。
YAML 解析器可以解析多语言文件,因为输入是有效的 JSON(每个 JSON 文件也是一个有效的 YAML 文件),并且它忽略未知键。它取Action_1的值,因为与 JSON 解析器不同,它进行精确的字段名匹配。
最后,XML 解析器可以解析多语言文件,因为它忽略所有周围的数据,只寻找看起来像 XML 的内容,而在这个多语言文件中,我们将这些内容隐藏在 JSON 值中。因此,它取Action_3的值。
我们构建的多语言文件是利用数据格式混淆攻击的强大初始载荷,类似于我们在上面探讨的 HashiCorp Vault 绕过(CVE-2020-16250)。
缓解措施
我们如何最小化这些风险,使 JSON 解析更加严格?我们希望:
- 在 JSON、XML 和 YAML 中禁止解析未知键。
- 在 JSON 和 XML 中禁止解析重复键。
- 在 JSON 中禁止不区分大小写的键匹配(这一点尤其重要!)。
- 在 XML 中禁止前置垃圾数据。
- 在 JSON 和 XML 中禁止后置垃圾数据。
遗憾的是,JSON 只提供了一个选项来使其解析更加严格:DisallowUnknownFields。顾名思义,这个选项禁止输入 JSON 中存在未知字段。YAML 通过KnownFields(true)函数支持相同的功能,尽管曾有提议为 XML 实现相同功能,但被拒绝了。
为了防止其余的不安全默认行为,我们必须创建一个自定义的“临时”解决方案。下面的代码块展示了strictJSONParse函数,这是一个尝试使 JSON 解析更加严格的尝试,但它存在以下限制:
- 性能不佳:它需要两次解析 JSON 输入,这会显著降低性能。
- 检测不完整:一些边缘情况仍然无法被检测到,具体细节在函数注释中有说明。
- 难以广泛采用:由于这些安全措施没有作为安全默认值或可配置选项集成到库中,因此广泛采用的可能性不大。
尽管如此,如果你在代码库中发现了一个漏洞,也许这个不完美的解决方案可以帮助你暂时填补漏洞,直到你找到更持久的解决方案。
|
|
JSON v2
要被广泛采用并从根本上解决问题,这种功能需要在库级别实现并默认启用。这就是 JSON v2 的作用。它目前只是一个提议,但已经投入了大量工作,希望它能尽快发布。它在许多方面都优于 JSON v1,包括:
- 禁止重复名称:“在 v2 中,具有重复名称的 JSON 对象会导致错误。
jsontext.AllowDuplicateNames选项控制这种行为差异。” - 进行区分大小写的匹配:“在 v2 中,字段匹配使用精确的、区分大小写的匹配。
MatchCaseInsensitiveNames和jsonv1.MatchCaseSensitiveDelimiter选项控制这种行为差异。” - 它包含了一个
RejectUnknownMembers选项,尽管它没有默认启用(类似于DisallowUnknownFields)。 - 它包含了一个
UnmarshalRead函数,用于处理来自io.Reader的数据,验证是否找到 EOF,禁止尾随垃圾数据。
尽管这个提议解决了本文讨论的许多问题,但在 Go 生态系统中,这些挑战将持续存在,因为广泛采用需要时间。在正式接受提议之后,开发人员必须将其集成到所有现有的 Go JSON 解析代码中。在此之前,这些漏洞将继续构成风险。
Go 开发者需要关注的关键要点
- 默认实现严格解析。对于 JSON,使用
DisallowUnknownFields;对于 YAML,使用KnownFields(true)。遗憾的是,这是你直接使用 Go 解析器原生API 能做到的全部。 - 在边界处保持一致性。当输入在多个服务中被处理时,通过始终使用相同的解析器或实现额外的验证层(例如上面展示的
strictJSONParse函数)来确保一致的解析行为。 - 关注 JSON v2。密切关注 Go 的 JSON v2 库的开发,它通过更安全的默认设置解决了许多这些问题。
- 利用静态分析。使用我们提供的 Semgrep 规则来检测代码库中的某些易受攻击的模式,特别是错误使用
-标签和omitempty字段。可以使用以下命令尝试:semgrep -c r/trailofbits.go.unmarshal-tag-is-dash和semgrep -c r/trailofbits.go.unmarshal-tag-is-omitempty!
尽管我们提供了缓解和检测策略,但长期解决方案需要对这些解析器的工作方式做出根本性改变。在解析器库采用安全默认设置之前,开发人员必须保持警惕。